import tensorflow as tf print(tf. version )
In [1]:
2.0.0
In [2]:
!pip install nltk
Processing c:\users\win10\appdata\local\pip\cache\wheels\de\5e\42\64a baeca668161c3e2cecc24f864a8fc421e3d07a104fc8a51\nltk-3.5-py3-none-an y.whl
Collecting tqdm
Downloading tqdm-4.49.0-py2.py3-none-any.whl (69 kB) Collecting regex
Using cached regex-2020.7.14-cp36-cp36m-win_amd64.whl (268 kB) Collecting joblib
Using cached joblib-0.16.0-py3-none-any.whl (300 kB) Collecting click
Using cached click-7.1.2-py2.py3-none-any.whl (82 kB) Installing collected packages: tqdm, regex, joblib, click, nltk
Successfully installed click-7.1.2 joblib-0.16.0 nltk-3.5 regex-2020.
7.14 tqdm-4.49.0
import csv
import tensorflow as tf
import numpy as np
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from nltk.corpus import stopwords
STOPWORDS = set(stopwords.words('english'))
In [3]:
Put the hyparameters at the top like this to make it easier to change and edit.
vocab_size = 5000
embedding_dim = 64
max_length = 200 trunc_type = 'post' padding_type = 'post' oov_tok = '<OOV>' training_portion = .8
In [4]:
First, let's define two lists that containing articles and labels. In the meantime, we remove stopwords.
articles = [] labels = []
with open("bbc-text.csv", 'r') as csvfile: reader = csv.reader(csvfile, delimiter=',') next(reader)
for row in reader: labels.append(row[0]) article = row[1]
for word in STOPWORDS:
token = ' ' + word + ' '
article = article.replace(token, ' ') article = article.replace(' ', ' ')
articles.append(article) print(len(labels)) print(len(articles))
In [5]:
2225
2225
There are only 2,225 articles in the data. Then we split into training set and validation set, according to the parameter we set earlier, 80% for training, 20% for validation.
train_size = int(len(articles) * training_portion)
train_articles = articles[0: train_size] train_labels = labels[0: train_size]
validation_articles = articles[train_size:] validation_labels = labels[train_size:]
print(train_size) print(len(train_articles)) print(len (train_labels)) print(len(validation_articles)) print(len (validation_labels))
In [6]:
1780
1780
1780
445
445
Tokenizer does all the heavy lifting for us. In our articles that it was tokenizing, it will take 5,000 most common words. oov_token is to put a special value in when an unseen word is encountered. This means I want "OOV" in bracket to be used to for words that are not in the word index. "fit_on_text" will go through all the text and create dictionary like this:
tokenizer = Tokenizer(num_words = vocab_size, oov_token=oov_tok) tokenizer.fit_on_texts(train_articles)
word_index = tokenizer.word_index
In [7]:
You can see that "OOV" in bracket is number 1, "said" is number 2, "mr" is number 3, and so on.
In [8]:
Out[8]:
dict(list(word_index.items())[0:10])
{'<OOV>': 1,
'said': 2,
'mr': 3,
'would': 4,
'year': 5,
'also': 6,
'people': 7,
'new': 8,
'us': 9,
'one': 10}
This process cleans up our text, lowercase, and remove punctuations.
After tokenization, the next step is to turn thoes tokens into lists of sequence.
train_sequences = tokenizer.texts_to_sequences(train_articles)
In [9]:
This is the 11th article in the training data that has been turned into sequences.
In [10]:
print(train_sequences[10])
[2431, 1, 225, 4996, 22, 642, 587, 225, 4996, 1, 1, 1663, 1, 1, 2431,
22, 565, 1, 1, 140, 278, 1, 140, 278, 796, 823, 662, 2307, 1, 1144, 1
694, 1, 1721, 4997, 1, 1, 1, 1, 1, 4738, 1, 1, 122, 4514, 1, 2, 2874,
1505, 352, 4739, 1, 52, 341, 1, 352, 2172, 3962, 41, 22, 3795, 1, 1,
1, 1, 543, 1, 1, 1, 835, 631, 2366, 347, 4740, 1, 365, 22, 1, 787, 23
67, 1, 4302, 138, 10, 1, 3666, 682, 3531, 1, 22, 1, 414, 823, 662, 1,
90, 13, 633, 1, 225, 4996, 1, 599, 1, 1694, 1021, 1, 4998, 808, 1864,
117, 1, 1, 1, 2974, 22, 1, 99, 278, 1, 1608, 4999, 543, 493, 1, 1443,
4741, 778, 1320, 1, 1861, 10, 33, 642, 319, 1, 62, 478, 565, 301, 150
6, |
22, 479, 1, 1, 1666, 1, 797, 1, 3066, 1, 1365, |
6, 1, 2431, 565, 2 |
2, |
2971, 4735, 1, 1, 1, 1, 1, 850, 39, 1825, 675, |
297, 26, 979, 1, 88 |
2, |
22, 361, 22, 13, 301, 1506, 1343, 374, 20, 63, |
883, 1096, 4303, 24 |
7] |
|
|
When we train neural networks for NLP, we need sequences to be in the same size, that's why we use padding. Our max_length is 200, so we use pad_sequences to make all of our articles the same length which is 200 in my example. That's why you see that the 1st article
was 426 in length, becomes 200, the 2nd article was 192 in length, becomes 200, and so on.
In [11]: train_padded = pad_sequences(train_sequences, maxlen=max_length, paddi
print(len(train_sequences[0])) print(len(train_padded[ 0]))
print(len(train_sequences[1])) print(len(train_padded[ 1]))
print(len(train_sequences[10])) print(len(train_padded[ 10]))
In [12]:
425
200
192
200
186
200
In addtion, there is padding type and truncating type, there are all "post". Means for example, for the 11th article, it was 186 in length, we padded to 200, and we padded at the end, add 14 zeros.
In [13]:
print(train_sequences[10])
[2431, 1, 225, 4996, 22, 642, 587, 225, 4996, 1, 1, 1663, 1, 1, 2431,
22, 565, 1, 1, 140, 278, 1, 140, 278, 796, 823, 662, 2307, 1, 1144, 1
694, 1, 1721, 4997, 1, 1, 1, 1, 1, 4738, 1, 1, 122, 4514, 1, 2, 2874,
1505, 352, 4739, 1, 52, 341, 1, 352, 2172, 3962, 41, 22, 3795, 1, 1,
1, 1, 543, 1, 1, 1, 835, 631, 2366, 347, 4740, 1, 365, 22, 1, 787, 23
67, 1, 4302, 138, 10, 1, 3666, 682, 3531, 1, 22, 1, 414, 823, 662, 1,
90, 13, 633, 1, 225, 4996, 1, 599, 1, 1694, 1021, 1, 4998, 808, 1864,
117, 1, 1, 1, 2974, 22, 1, 99, 278, 1, 1608, 4999, 543, 493, 1, 1443,
4741, 778, 1320, 1, 1861, 10, 33, 642, 319, 1, 62, 478, 565, 301, 150
6, 22, 479, 1, 1, 1666, 1, 797, 1, 3066, 1, 1365, 6, 1, 2431, 565, 2
2, 2971, 4735, 1, 1, 1, 1, 1, 850, 39, 1825, 675, 297, 26, 979, 1, 88
2, 22, 361, 22, 13, 301, 1506, 1343, 374, 20, 63, 883, 1096, 4303, 24
7]
print(train_padded[10])
In [14]:
[2431 |
1 |
225 |
4996 |
22 |
642 |
587 |
225 |
4996 |
1 |
1 |
1663 |
1 |
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
2431 |
22 |
565 |
1 |
1 |
140 |
278 |
1 |
140 |
278 |
796 |
823 |
662 |
230 |
7
1 1144 1694 1 1721 4997 1 1 1 1 1 4738 1
1
122 4514 1 2 2874 1505 352 4739 1 52 341 1 352 217
2
3962 41 22 3795 1 1 1 1 543 1 1 1 835 63
1
2366 347 4740 1 365 22 1 787 2367 1 4302 138 10
1
3666 682 3531 1 22 1 414 823 662 1 90 13 633
1
225 4996 1 599 1 1694 1021 1 4998 808 1864 117 1
1
1 2974 22 1 99 278 1 1608 4999 543 493 1 1443 474
1
778 1320 1 1861 10 33 642 319 1 62 478 565 301 150
6
22 479 1 1 1666 1 797 1 3066 1 1365 6 1 243
1
565 22 2971 4735 1 1 1 1 1 850 39 1825 675 29
7
26 979 1 882 22 361 22 13 301 1506 1343 374 20 6
3
883 1096 4303 247 0 0 0 0 0 0 0 0 0
0
0 0 0 0]
And for the 1st article, it was 426 in length, we truncated to 200, and we truncated at the end.
In [15]:
print(train_sequences[0])
[91, 160, 1141, 1106, 49, 979, 755, 1, 89, 1304, 4289, 129, 175, 365
4, 1214, 1195, 1578, 42, 7, 893, 91, 1, 334, 85, 20, 14, 130, 3262, 1
215, 2421, 570, 451, 1376, 58, 3378, 3521, 1661, 8, 921, 730, 10, 84
4, 1, 9, 598, 1579, 1107, 395, 1941, 1106, 731, 49, 538, 1398, 2012,
1623, 134, 249, 113, 2355, 795, 4981, 980, 584, 10, 3957, 3958, 921,
2562, 129, 344, 175, 3654, 1, 1, 39, 62, 2867, 28, 9, 4723, 18, 1305,
136, 416, 7, 143, 1423, 71, 4501, 436, 4982, 91, 1107, 77, 1, 82, 201
3, 53, 1, 91, 6, 1008, 609, |
89, 1304, 91, 1964, 131, 137, 420, |
9, |
286 |
8, 38, 152, 1234, 89, 1304, |
4724, 7, 436, 4982, 3154, 6, 2492, |
1, |
43 |
1, 1126, 1, 1424, 571, 1261, 1902, 1, 766, 9, 538, 1398, 2012, |
134, 2 |
||
069, 400, 845, 1965, 1601, 34, 1717, 2869, 1, 1, 2422, 244, 9, |
2624, |
||
82, 732, 6, 1173, 1196, 152, 720, 591, 1, 124, 28, 1305, 1690, |
432, 8 |
||
3, 933, 115, 20, 14, 18, 3155, 1, 37, 1484, 1, 23, 37, 87, 335, 2356,
37, 467, 255, 1965, 1359, 328, 1, 299, 732, 1174, 18, 2870, 1717, 1,
294, 756, 1074, 395, 2014, 387, 431, 2014, 2, 1360, 1, 1717, 2166, 6
7, 1, 1, 1718, 249, 1662, 3059, 1175, 395, 41, 878, 246, 2792, 345, 5
3, 548, 400, 2, 1, 1, 655, 1361, 203, 91, 3959, 91, 90, 42, 7, 320, 3
95, 77, |
893, 1, 91, 1106, 400, 538, 9, 845, |
2422, 11, 38, 1, 995, 51 |
||
4, 483, |
2070, 160, 572, 1, 128, 7, 320, 77, |
893, 1216, 1126, 1463, 34 |
||
6, 54, 2214, 1217, 741, 92, 256, 274, 1019, 71, 623, 346, 2423, 756, |
||||
1215, 2357, 1719, 1, 3784, 3522, 1, 1126, 2014, 177, |
371, |
1399, 77, 5 |
||
3, 548, 105, 1141, 3, 1, 1047, 93, 2962, 1, 2625, 1, |
102, |
902, 440, 4 |
||
52, 2, 3, 1, 2871, 451, 1425, 43, 77, 429, 31, 8, 1019, 921, 1, 2562,
30, 1, 91, 1691, 879, 89, 1304, 91, 1964, 1, 30, 8, 1624, 1, 1, 4290,
1580, 4289, 656, 1, 3785, 1008, 572, 4291, 2867, 10, 880, 656, 58, 1,
1262, 1, 1, 91, 1554, 934, 4723, 1, 577, 4106, 10, 9, 235, 2012, 91,
134, 1, 95, 656, 3263, |
1, 58, 520, 673, 2626, 3785, 4983, 3379, 483, |
4725, 39, 4501, 1, 91, |
1748, 673, 269, 116, 239, 2627, 354, 644, 58, |
4107, 757, 3655, 4723, |
146, 1, 400, 7, 71, 1749, 1107, 767, 910, 118, |
584, 3380, 1316, 1579, |
1, 1602, 7, 893, 77, 77] |
print(train_padded[0])
In [16]:
[ |
91 |
160 |
1141 |
1106 |
49 |
979 |
755 |
1 |
89 |
1304 |
4289 |
129 |
175 |
365 |
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1214 |
1195 |
1578 |
42 |
7 |
893 |
91 |
1 |
334 |
85 |
20 |
14 |
130 |
326 |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1215 |
2421 |
570 |
451 |
1376 |
58 |
3378 |
3521 |
1661 |
8 |
921 |
730 |
10 |
84 |
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
9 |
598 |
1579 |
1107 |
395 |
1941 |
1106 |
731 |
49 |
538 |
1398 |
2012 |
162 |
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
134 |
249 |
113 |
2355 |
795 |
4981 |
980 |
584 |
10 |
3957 |
3958 |
921 |
2562 |
12 |
9 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
344 |
175 |
3654 |
1 |
1 |
39 |
62 |
2867 |
28 |
9 |
4723 |
18 |
1305 |
13 |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
416 |
7 |
143 |
1423 |
71 |
4501 |
436 |
4982 |
91 |
1107 |
77 |
1 |
82 |
201 |
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
53 |
1 |
91 |
6 |
1008 |
609 |
89 |
1304 |
91 |
1964 |
131 |
137 |
420 |
|
9 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2868 |
38 |
152 |
1234 |
89 |
1304 |
4724 |
7 |
436 |
4982 |
3154 |
6 |
2492 |
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
431 |
1126 |
1 |
1424 |
571 |
1261 |
1902 |
1 |
766 |
9 |
538 |
1398 |
2012 |
13 |
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2069 |
400 |
845 |
1965 |
1601 |
34 |
1717 |
2869 |
1 |
1 |
2422 |
244 |
9 |
262 |
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
82 |
732 |
6 |
1173 |
1196 |
152 |
720 |
591 |
1 |
124 |
28 |
1305 |
1690 |
43 |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
83 |
933 |
115 |
20 |
14 |
18 |
3155 |
1 |
37 |
1484 |
1 |
23 |
37 |
8 |
7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
335 |
2356 |
37 |
467 |
255 |
1965 |
1359 |
328 |
1 |
299 |
732 |
1174 |
18 |
287 |
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1717 1 294 756]
Then we do the same for the validation sequences. Note that we should expect more out of vocabulary words from validation articles because word index were derived from the training articles.
In [17]:
validation_sequences = tokenizer.texts_to_sequences(validation_article validation_padded = pad_sequences(validation_sequences, maxlen=max_len
print(len(validation_sequences)) print(validation_padded.shape)
445
(445, 200)
Now we are going to look at the labels. because our labels are text, so we will tokenize them, when training, labels are expected to be numpy arrays. So we will turn list of labels into numpy arrays like so:
print(set(labels))
In [18]:
{'politics', 'entertainment', 'tech', 'sport', 'business'}
label_tokenizer = Tokenizer() label_tokenizer.fit_on_texts(labels)
training_label_seq = np.array(label_tokenizer.texts_to_sequences(train validation_label_seq = np.array(label_tokenizer.texts_to_sequences(val
In [19]:
print(training_label_seq[0]) print(training_label_seq[1]) print(training_label_seq[2]) print(training_label_seq.shape)
print(validation_label_seq[0]) print(validation_label_seq[1]) print(validation_label_seq[2]) print(validation_label_seq.shape)
In [20]:
[4]
[2]
[1]
(1780, 1)
[5]
[4]
[3]
(445, 1)
Before training deep neural network, we want to explore what our original article and article after padding look like. Running the following code, we explore the 11th article, we can see that some words become "OOV", because they did not make to the top 5,000.
In [22]:
reverse_word_index = dict([(value, key) for (key, value) in word_index
def decode_article(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text]) print(decode_article(train_padded[10]))
print('---') print(train_articles[10])
berlin <OOV> anti nazi film german movie anti nazi <OOV> <OOV> drawn
<OOV> <OOV> berlin film festival <OOV> <OOV> final days <OOV> final d ays member white rose movement <OOV> 21 arrested <OOV> brother hans < OOV> <OOV> <OOV> <OOV> <OOV> tyranny <OOV> <OOV> director marc <OOV> said feeling responsibility keep legacy <OOV> going must <OOV> keep i deas alive added film drew <OOV> <OOV> <OOV> <OOV> trial <OOV> <OOV>
<OOV> east germany secret police discovery <OOV> behind film <OOV> wo rked closely <OOV> relatives including one <OOV> sisters ensure histo rical <OOV> film <OOV> members white rose <OOV> group first started < OOV> anti nazi <OOV> summer <OOV> arrested dropped <OOV> munich unive rsity calling day <OOV> <OOV> <OOV> regime film <OOV> six days <OOV> arrest intense trial saw <OOV> initially deny charges ended <OOV> app earance one three german films <OOV> top prize festival south african film version <OOV> <OOV> opera <OOV> shot <OOV> town <OOV> language a lso <OOV> berlin festival film entitled u <OOV> <OOV> <OOV> <OOV> <OO V> story set performed 40 strong music theatre <OOV> debut film perfo rmance film first south african feature 25 years second nominated gol den bear award ? ? ? ? ? ? ? ? ? ? ? ? ? ?
---
berlin cheers anti-nazi film german movie anti-nazi resistance heroin e drawn loud applause berlin film festival. sophie scholl - final da ys portrays final days member white rose movement. scholl 21 arrest ed beheaded brother hans 1943 distributing leaflets condemning abh orrent tyranny adolf hitler. director marc rothemund said: feeling responsibility keep legacy scholls going. must somehow keep ideas a live added. film drew transcripts gestapo interrogations scholl tr ial preserved archive communist east germany secret police. discovery inspiration behind film rothemund worked closely surviving relatives including one scholl sisters ensure historical accuracy film. scholl members white rose resistance group first started distributing anti-n azi leaflets summer 1942. arrested dropped leaflets munich university calling day reckoning adolf hitler regime. film focuses six days sc holl arrest intense trial saw scholl initially deny charges ended def iant appearance. one three german films vying top prize festival. so uth african film version bizet tragic opera carmen shot cape town xho sa language also premiered berlin festival. film entitled u-carmen ek hayelitsha carmen khayelitsha township story set. performed 40-strong music theatre troupe debut film performance. film first south african feature 25 years second nominated golden bear award.
Now we can implement LSTM. Here is my code that I build a tf.keras.Sequential model and start with an embedding layer. An embedding layer stores one vector per word. When called, it converts the sequences of word indices into sequences of vectors. After training, words with similar meanings often have the similar vectors.
Next is how to implement LSTM in code. The Bidirectional wrapper is used with a LSTM layer, this propagates the input forwards and backwards through the LSTM layer and then concatenates the outputs. This helps LSTM to learn long term dependencies. We then fit it to a dense neural network to do classification.
model = tf.keras.Sequential([
# Add an Embedding layer expecting input vocab of size 5000, and o tf.keras.layers.Embedding(vocab_size, embedding_dim), tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim))
# tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)),
# use ReLU in place of tanh function since they are very good alte
tf.keras.layers.Dense(embedding_dim, activation='relu'),
# Add a Dense layer with 6 units and softmax activation.
# When we have multiple outputs, softmax convert outputs layers in
tf.keras.layers.Dense(6, activation='softmax')
])
model.summary()
In [39]:
Model: "sequential_3"
Layer (type) Output Shape Param #
=================================================================
embedding_3 (Embedding) |
(None, |
None, |
64) |
320000 |
|
bidirectional_3 (Bidirection |
(None, |
128) |
|
66048 |
dense_6 (Dense) |
(None, |
64) |
|
8256 |
dense_7 (Dense) |
(None, |
6) |
|
390 |
=================================================================
Total params: 394,694
Trainable params: 394,694
Non-trainable params: 0
In our model summay, we have our embeddings, our Bidirectional contains LSTM, followed by two dense layers. The output from Bidirectional is 128, because it doubled what we put in LSTM. We can also stack LSTM layer but I found the results worse.
In [40]: model.compile(loss='sparse_categorical_crossentropy', optimizer= 'adam'
num_epochs = 10
history = model.fit(train_padded, training_label_seq, epochs=num_epoch
In [41]:
Train on 1780 samples, validate on 445 samples Epoch 1/10
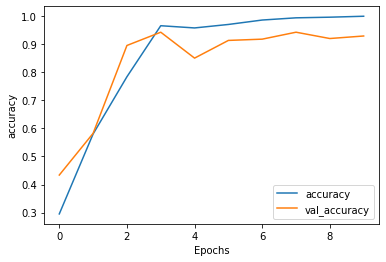
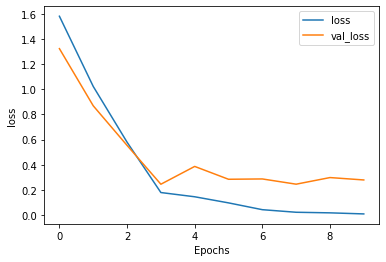
1780/1780 - 7s - loss: 1.5802 - accuracy: 0.2955 - val_loss: 1.3228 -val_accuracy: 0.4337
Epoch 2/10
1780/1780 - 5s - loss: 1.0225 - accuracy: 0.5798 - val_loss: 0.8686 -val_accuracy: 0.5820
Epoch 3/10
1780/1780 - 5s - loss: 0.5797 - accuracy: 0.7831 - val_loss: 0.5539 -val_accuracy: 0.8944
Epoch 4/10
1780/1780 - 5s - loss: 0.1793 - accuracy: 0.9646 - val_loss: 0.2454 -val_accuracy: 0.9416
Epoch 5/10
1780/1780 - 5s - loss: 0.1457 - accuracy: 0.9567 - val_loss: 0.3868 -val_accuracy: 0.8494
Epoch 6/10
1780/1780 - 5s - loss: 0.0972 - accuracy: 0.9691 - val_loss: 0.2848 -val_accuracy: 0.9124
Epoch 7/10
1780/1780 - 5s - loss: 0.0431 - accuracy: 0.9848 - val_loss: 0.2873 -val_accuracy: 0.9169
Epoch 8/10
1780/1780 - 5s - loss: 0.0226 - accuracy: 0.9927 - val_loss: 0.2457 -val_accuracy: 0.9416
Epoch 9/10
1780/1780 - 5s - loss: 0.0179 - accuracy: 0.9949 - val_loss: 0.2983 -val_accuracy: 0.9191
Epoch 10/10
1780/1780 - 5s - loss: 0.0094 - accuracy: 0.9983 - val_loss: 0.2793 -val_accuracy: 0.9281
In [42]:
!pip install matplotlib
Requirement already satisfied: matplotlib in c:\users\win10\.conda\en vs\tensorflow2\lib\site-packages (3.3.2)
Requirement already satisfied: certifi>=2020.06.20 in c:\users\win10
\.conda\envs\tensorflow2\lib\site-packages (from matplotlib) (2020.6. 20)
Requirement already satisfied: numpy>=1.15 in c:\users\win10\.conda\e nvs\tensorflow2\lib\site-packages (from matplotlib) (1.19.1) Requirement already satisfied: python-dateutil>=2.1 in c:\users\win10
\.conda\envs\tensorflow2\lib\site-packages (from matplotlib) (2.8.1) Requirement already satisfied: cycler>=0.10 in c:\users\win10\.conda
\envs\tensorflow2\lib\site-packages (from matplotlib) (0.10.0) Requirement already satisfied: kiwisolver>=1.0.1 in c:\users\win10\.c onda\envs\tensorflow2\lib\site-packages (from matplotlib) (1.2.0) Requirement already satisfied: pillow>=6.2.0 in c:\users\win10\.conda
\envs\tensorflow2\lib\site-packages (from matplotlib) (7.2.0) Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.
0.3 in c:\users\win10\.conda\envs\tensorflow2\lib\site-packages (from matplotlib) (2.4.7)
Requirement already satisfied: six>=1.5 in c:\users\win10\.conda\envs
\tensorflow2\lib\site-packages (from python-dateutil>=2.1->matplotli b) (1.15.0)
In [ ]:
from matplotlib import pyplot as plt
def plot_graphs(history, string): plt.plot(history.history[string]) plt.plot(history.history[ 'val_'+string]) plt.xlabel( "Epochs")
plt.ylabel(string) plt.legend([string, 'val_'+string]) plt.show()
plot_graphs(history, "accuracy") plot_graphs(history, "loss")
In [43]:
|
txt = ["A WeWork shareholder has taken the company to court over the n seq = tokenizer.texts_to_sequences(txt) padded = pad_sequences(seq, maxlen=max_length) pred = model.predict(padded) pred |
||
|
|
|
|
In [44]:
Out[44]: array([[0.11773098, 0.11342432, 0.05740624, 0.43609414, 0.12342227,
0.15192208]], dtype=float32)
In [48]:
|
txt = ["A WeWork shareholder has taken the company to court over the n seq = tokenizer.texts_to_sequences(txt) padded = pad_sequences(seq, maxlen=max_length) pred = model.predict(padded) labels = ['sport', 'bussiness', 'politics', 'tech', 'entertainment','u print(pred, labels[np.argmax(pred)]) |
||
|
|
||
[[0.11773098 0.11342432 0.05740624 0.43609414 0.12342227 0.15192208]]
tech
np.argmax(pred)
In [49]:
Out[49]: 3
In [ ]: