Suppose, We're in a situation to create a Sentiment analysis model, we have the dataset available but the problem here is machine will not going to understand the sentences of any languages, we have to clean those dataset by using stopwords, deleting punctuation and many more irrelevant things inside the data and We have to make it upto that level where we can feed those data to our machine or deep learning algorithms from that we can get some output with it.
We are assuming you have a knowledge of Python, and if not, nothing to worry, we will give you some overview of it.
1.Python String
A String is like a sequence of Characters.
A character is just a symbol.Like, the English language has 26 characters.
Computers don't deal with characters,they deal with binary(numbers) only. Even though you seen characters but internally it is stored and manipulated with the combination of 0's and 1's. The conversion of character to a number is known as encoding, and the reverse is decoding.
String literally surrounded by a single or double quotations like:
a = "LiveAdmins" print(a)
In [1]:
LiveAdmins
Strings are arrays
Like in other popular programming languages, strings in Python are arrays of bytes represents unicode characters.
However, Python doesn't have the character as the datatype, single character is just simply a string with length of 1.
We used square bracket to access elements from the string.
#Get the character at position 4(Here, indexing starts from 0)
a = "LiveAdmins" print(a[ 4])
In [2]:
A
Slicing
You can get the output upto certain range of characters by using the slicing index.
#To get the output from the position 3 to 6(not included)
a = "LiveAdmins" print(a[ 3: 6])
print("-" * 50)
#To get the output by negative indexing from -6 position to -2 positio
print(a[-6: -2])
print("-" * 50)
#Get the results from position 2 to 6 but give result with the increme
print(a[2: 6: 2])
In [3]:
eAd
Admi
vA
String Methods
Python have set of built-in methods that you can use on strings.
In [4]:
#strip() will remove whitespace in the string from begining to the end
a = " LiveAdmins " print(a.split())
['LiveAdmins']
#lower() will lowercase the words which are upper in the sentences.
a = "LiveAdmins" print(a.lower())
#upper() will transform lowercase into upper.
print(a.upper())
In [5]:
liveadmins LIVEADMINS
#replace() will work like replace one string with another string.
a = "LiveAdmins" print(a.replace("Live", "L"))
In [6]:
LAdmins
In [7]:
#split() will split the strings into substrings if it finds any instan
a = "Live.Admins" print(a.split("."))
['Live', 'Admins']
String Concatenation
To concatenate or combine two strings by use of + operator.
a = "LiveAdmins"
b = "Data" print(a +" "+ b)
In [8]:
LiveAdmins Data
Import text
In NLP your dataset would be in .txt, .csv type of format, you need to import it and try to clean the irrelevant datas from the dataset.Here we'll going to understand Python file handling:create,open,read,append,write.
Create a text file
With the use of python you can create the text files by using code,we have demostrated here how you can do this.
#Step1
from google.colab import files files.upload()
file = open("LiveAdmins.txt", "w+")
In [9]:
ModuleNotFoundError Traceback (most recent call last)
Cell In[9], line 2
1 #Step1
----> 2 from google.colab import files
3 files.upload()
4 file = open("LiveAdmins.txt", "w+") ModuleNotFoundError: No module named 'google'
Here we declared file as a variable to open a file named LiveAdmins.txt.Open takes two arguemnets, first one is for the file we want to open and second one represents some kind of permissions or operation we want to do into that file.
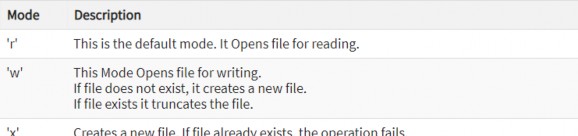
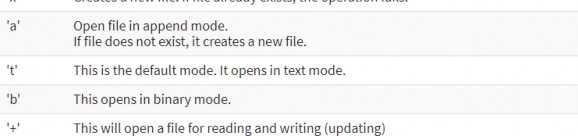
Here we taken "w" letter as an arguemnt, which indicates write and will create a file if it is not exist in the library.
That "+" signs indicate both read and write.
The other option beside "w" are, "r" for read, and "a" for append.
#Step2
for i in range( 5):
file.write("Line number is %d\r\n" % (i+ 1))
In [ ]:
We have a loop that runs over a range of 5 numbers.
Here using the Write function for entering data into the file.
The Output we want to iterate in the file is "Line number is", which we already declared with write function and then percent d(display integers)
#Step3
file.close()
In [10]:
NameError Traceback (most recent call last)
Cell In[10], line 3
1 #Step3
----> 3 file.close()
NameError: name 'file' is not defined
This will close the instance of the file LiveAdmins.txt stored.
2
Type Markdown and LaTeX: 𝛼
Append data to a file
You can also append a new text inside the existing file or in a new file.
#Step1
file = open("LiveAdmins.txt", "a+")
In [ ]:
Once again "+" sign is in the code which means if .txt file are not available, this plus sign will create a new file but here is not any requirement to create a new file.
#Step2
for i in range( 3):
file.write("Appending Line number %d\r\n" %(i+ 1))
In [ ]:
This will write data into a file in append mode.
#Step3
file.close()
In [ ]:
We seen earlier this close function will close the instance of the file LiveAdmins.txt stored.
Read the files
Not only you create .txt files in Python but you can also call .txt file in a "read mode"(r).
#Step1. Open the file in read mode
file = open("LiveAdmins.txt", "r")
In [11]:
FileNotFoundError Traceback (most recent call last)
Cell In[11], line 3
1 #Step1. Open the file in read mode
----> 3 file = open("LiveAdmins.txt", "r")
File ~/anaconda3/lib/python3.11/site-packages/IPython/core/interactiv eshell.py:286, in _modified_open(file, *args, **kwargs)
-
if file in {0, 1, 2}:
-
raise ValueError(
-
f"IPython won't let you open fd={file} by default "
"as it is likely to crash IPython. If you know what y ou are doing, "
"you can use builtins' open."
284 )
--> 286 return io_open(file, *args, **kwargs)
FileNotFoundError: [Errno 2] No such file or directory: 'LiveAdmins.t xt'
In [ ]:
#Step2. Here we'll check, is our file is open or not, if yes we procee
if file.mode == 'r':
content = file.read() #We used file.read() for reading the file da
#Step3. Printing the file
print(content)
print("Here is the output!")
In [ ]:
Line number is 1 Line number is 2 Line number is 3 Line number is 4 Line number is 5
Appending Line number 1 Appending Line number 2 Appending Line number 3
Here is the output!
In [ ]:
Files mode in Python
Web Scraping with Python
Suppose you have to pull large amount of data from websites and you want to fetch it as quickly as possible. How would you do it? Manually going to the website and collect those datas.It will be tedious work. So, "web scrapping" will help you out in this situation. Web scrapping just makes this job easier and faster.
Here, we will do Web Scrapping with Python, starts with
-
Why we do web scrapping? Web scrapping will be used to collect large amount of data from Websites.But why does someone have to collect such large amount of data from websites? To know about this, let's have to look at the applications of web scrapping:
Price comaparison: Parsehub is providing such services to useweb scraping to collect data from some online shopping websites and use to comapre price of products from another.
Gathering Emails: There are lots of companies that use emails as a medium for marketing, they use web scrapping to collect email id's and send bulk emails.
Social media scrapping: Web scrapping is used to collect data from Social Media websites such as Twitter to find out what's trending in twitter.
Research and Development: For reasearch purposes people do web scrapping to collect a large set of data(Statistics, General information, temperature,etc.) from
websites, which are analyzed and used to carry out surveys or for R&D.
-
What is Web scrapping and is it legal or not? Web scrapping is an automated to extract large amount of data from websites.And the websites data are unstructured most of the time.Web scrapping will help you out to collect those unstructured data and stored it in a structured form.There are different ways to scrape websites such as online
services,APIs, or by writing your own code. Here, we'll see how to implementing the web scraping with python.
Coming to the question, is scrapping legal or not? Some websites allow web scrapping and some not.To know whether website allows you to scrape it or not by website's "robots.txt" file. You can find this file just append "/robots.txt" to the URL that you want to scrape.Here, we're scrapping from Flipkart website.So, to see the "robots.txt" file, URL is
www.flipkart.com/robots.txt ( http://www.flipkart.com/robots.txt).
-
How does web scrapping work?
When we run the code for web scraping, a request is sent to the URL that you have mentioned in the code. As a response to the request, the server send the data and allows you to read the HTML or XML page. Then our code will parses the HTML or XML page, find the data and extract it.
To extract datas using web scraping with python, you need to follow these basic steps:
1.Find that URL that you mentioned in the code and want to scrape it. 2.Inspect the Page for scraping. 3.Find those data you want to extract. 4.Write the code for scrapping. 5.Run the code and extract the data. 6.Store the data in the required format.
Now lets see how to extract data from the flipkart website using Python.
-
Libraries used for Web scrapping
We already know, that python used for various applications and there are different libraries for different purposes.In this, we're using the following libraries:
Selenium: Selenium library is used for web testing. We will use to automate browser activities.
BeautifulSoup4: It is generally used for parsing HTML and XML documents.It creates a parse trees that is helpful to extract the datas easily.
Pandas: It is a Python library used for data manipulation and analysis.Pandas is used to extract data and stored it in the desired format.
For Demo Purpose : Scrapping a Flipkart Website Pre-requisites:
Python 3.x with Selenium, Beautifulsoup4, Pandas library installed. Google Chrome Browser
You can go through this link ( https://github.com/iNeuronai/webscrappper_text.git) for more
In [ ]:
Text Preprocessing
Supose we have textual data available, we need to apply many of pre-processing steps to the data to transform those words into numerical features that work with machine learning algorithms.
The pre-processing steps for the problem depend mainly on the domain and the problem itself.We don't need to apply all the steps for every problem.
# import necessary libraries
import nltk import string import re
In [1]:
Text lowercase
We do lowercase the text to reduce the size of the vocabulary of our text data.
def lowercase_text(text):
return text.lower()
input_str = "Weather is too Cloudy.Possiblity of Rain is High,Today!!" lowercase_text(input_str)
In [2]:
Out[2]: 'weather is too cloudy.possiblity of rain is high,today!!'
Remove numbers
We should either remove the numbers or convert those numbers into textual representations. We use regular expressions(re) to remove the numbers.
# For Removing numbers
def remove_num(text):
result = re.sub(r'\d+', '', text)
return result
input_s = "You bought 6 candies from shop, and 4 candies are in home." remove_num(input_s)
In [4]:
Out[4]: 'You bought candies from shop, and candies are in home.'
As we mentioned above,you can also convert the numbers into words. This could be done by using the inflect library.
# import the library
import inflect
q = inflect.engine()
# convert number into text
def convert_num(text):
# split strings into list of texts
temp_string = text.split() # initialise empty list new_str = []
for word in temp_string:
# if text is a digit, convert the digit
# to numbers and append into the new_str list
if word.isdigit():
temp = q.number_to_words(word) new_str.append(temp)
# append the texts as it is
else:
new_str.append(word)
# join the texts of new_str to form a string
temp_str = ' '.join(new_str)
return temp_str
input_str = 'You bought 6 candies from shop, and 4 candies are in home convert_num(input_str)
In [5]:
Out[5]: 'You bought six candies from shop, and four candies are in home.'
Remove Punctuation
We remove punctuations because of that we don't have different form of the same word. If we don't remove punctuations, then been, been, and been! will be treated separately.
# let's remove punctuation
def rem_punct(text):
translator = str.maketrans('', '', string.punctuation)
return text.translate(translator)
input_str = "Hey, Are you excited??, After a week, we will be in Shiml rem_punct(input_str)
In [ ]:
Out[23]: 'Hey Are you excited After a week we will be in Shimla'
Method---> str.maketrans()
The str.maketrans() method in Python is used to create a translation table that can be used with the str.translate() method to perform specific character replacements in a string. This is often used for tasks like removing or replacing certain characters in a string.
Here's what each argument in str.maketrans() means:
-
The first argument is the set of characters you want to replace. In this case, '' (empty string) means that you don't want to replace any characters.
-
The second argument is the set of characters you want to remove. In this case, string.punctuation is a string constant that contains all punctuation characters (like periods, commas, exclamation marks, etc.).
Putting it together, str.maketrans('', '', string.punctuation) creates a translation table that essentially says "don't replace any characters, but remove all punctuation characters."
You can then use this translation table with the str.translate() method to apply these replacements to a string. For example:
import string
translator = str.maketrans('', '', string.punctuation) text = "Hello, world! How are you?"
cleaned_text = text.translate(translator)
print(cleaned_text)
Output:
Hello world How are you
In this example, the cleaned_text variable will contain the original string with all punctuation removed.
In [ ]:
Remove default stopwords:
Stopwords are words that do not contribute to the meaning of the sentence. Hence, they can be safely removed without causing any change in the meaning of a sentence. The
NLTK(Natural Language Toolkit) library has the set of stopwords and we can use these to remove stopwords from our text and return a list of word tokens.
# importing nltk library
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
nltk.download('stopwords') nltk.download('punkt')
# remove stopwords function
def rem_stopwords(text):
stop_words = set(stopwords.words("english")) word_tokens = word_tokenize(text) print("++++++", word_tokens)
filtered_text = [word for word in word_tokens if word not in stop_
return filtered_text
ex_text = "Data is the new oil. A.I is the last invention" rem_stopwords(ex_text)
In [6]:
[nltk_data] Downloading package stopwords to /root/nltk_data... [nltk_data] Unzipping corpora/stopwords.zip.
[nltk_data] Downloading package punkt to /root/nltk_data... [nltk_data] Unzipping tokenizers/punkt.zip.
++++++ ['Data', 'is', 'the', 'new', 'oil', '.', 'A.I', 'is', 'the', 'last', 'invention']
Out[6]: ['Data', 'new', 'oil', '.', 'A.I', 'last', 'invention']
Stemming
From Stemming we will process of getting the root form of a word. Root or Stem is the part to which inflextional affixes(like -ed, -ize, etc) are added. We would create the stem words by removing the prefix of suffix of a word. So, stemming a word may not result in actual words.
For Example: Mangoes ---> Mango
Boys ---> Boy going ---> go
If our sentences are not in tokens, then we need to convert it into tokens. After we converted strings of text into tokens, then we can convert those word tokens into their root form. These are the Porter stemmer, the snowball stemmer, and the Lancaster Stemmer. We usually use Porter stemmer among them.
#importing nltk's porter stemmer
from nltk.stem.porter import PorterStemmer from nltk.tokenize import word_tokenize stem1 = PorterStemmer()
# stem words in the list of tokenised words
def s_words(text):
word_tokens = word_tokenize(text)
stems = [stem1.stem(word) for word in word_tokens]
return stems
text = 'Data is the new revolution in the World, in a day one individu s_words(text)
In [ ]:
Out[27]: ['data',
'is',
'the',
'new', 'revolut', 'in',
'the',
'world',
',',
'in',
'a',
'day',
'one', 'individu', 'would',
'gener', 'terabyt', 'of',
'data',
'.']
Lemmatization
As stemming, lemmatization do the same but the only difference is that lemmatization ensures that root word belongs to the language. Because of the use of lemmatization we will get the valid words. In NLTK(Natural language Toolkit), we use WordLemmatizer to get the
lemmas of words. We also need to provide a context for the lemmatization.So, we added pos(parts-of-speech) as a parameter.
from nltk.stem import wordnet
from nltk.tokenize import word_tokenize lemma = wordnet.WordNetLemmatizer() nltk.download('wordnet')
# lemmatize string
def lemmatize_word(text):
word_tokens = word_tokenize(text)
# provide context i.e. part-of-speech(pos)
lemmas = [lemma.lemmatize(word, pos ='v') for word in word_tokens]
return lemmas
text = 'Data is the new revolution in the World, in a day one individu lemmatize_word(text)
In [ ]:
[nltk_data] Downloading package wordnet to /root/nltk_data... [nltk_data] Unzipping corpora/wordnet.zip.
Out[28]: ['Data',
'be',
'the',
'new', 'revolution', 'in',
'the',
'World',
',',
'in',
'a',
'day',
'one', 'individual', 'would', 'generate', 'terabytes', 'of',
'data',
'.']
import nltk nltk.download('punkt')
In [ ]:
[nltk_data] Downloading package punkt to /root/nltk_data... [nltk_data] Package punkt is already up-to-date!
Out[29]: True
Parts of Speech (POS) Tagging
The pos(parts of speech) explain you how a word is used in a sentence. In the sentence, a word have different contexts and semantic meanings. The basic natural language processing(NLP) models like bag-of-words(bow) fails to identify these relation between the words. For that we use pos tagging to mark a word to its pos tag based on its context in the data. Pos is also used to extract rlationship between the words.
# importing tokenize library
from nltk.tokenize import word_tokenize from nltk import pos_tag nltk.download( 'averaged_perceptron_tagger')
# convert text into word_tokens with their tags
def pos_tagg(text):
word_tokens = word_tokenize(text)
return pos_tag(word_tokens)
pos_tagg('Are you afraid of something?')
In [ ]:
[nltk_data] Downloading package averaged_perceptron_tagger to [nltk_data] /root/nltk_data...
[nltk_data] Unzipping taggers/averaged_perceptron_tagger.zip.
Out[31]: [('Are', 'NNP'),
('you', 'PRP'),
('afraid', 'IN'),
('of', 'IN'),
('something', 'NN'),
('?', '.')]
In the above example NNP stands for Proper noun, PRP stands for personal noun, IN as Preposition. We can get all the details pos tags using the Penn Treebank tagset.
# downloading the tagset
nltk.download('tagsets')
# extract information about the tag
nltk.help.upenn_tagset('PRP')
In [ ]:
[nltk_data] Downloading package tagsets to
[nltk_data] C:\Users\User\AppData\Roaming\nltk_data... [nltk_data] Unzipping help\tagsets.zip.
PRP: pronoun, personal
hers herself him himself hisself it itself me myself one oneself
ours
ourselves ownself self she thee theirs them themselves they thou
thy us
Chunking
Chunking is the process of extracting phrases from the Unstructured text and give them more structure to it. We also called them shallow parsing.We can do it on top of pos tagging. It groups words into chunks mainly for noun phrases. chunking we do by using regular expression.
#importing libraries
from nltk.tokenize import word_tokenize
from nltk import pos_tag
# here we define chunking function with text and regular # expressions representing grammar as parameter
def chunking(text, grammar): word_tokens = word_tokenize(text)
# label words with pos
word_pos = pos_tag(word_tokens)
# create chunk parser using grammar
chunkParser = nltk.RegexpParser(grammar)
# test it on the list of word tokens with tagged pos
tree = chunkParser.parse(word_pos)
for subtree in tree.subtrees(): print(subtree)
#tree.draw()
sentence = 'the little red parrot is flying in the sky' grammar = "NP: {<DT>?<JJ>*<NN>}"
chunking(sentence, grammar)
In [ ]:
(S
(NP the/DT little/JJ red/JJ parrot/NN) is/VBZ
flying/VBG in/IN
(NP the/DT sky/NN))
(NP the/DT little/JJ red/JJ parrot/NN) (NP the/DT sky/NN)
In the above example, we defined the grammar by using the regular expression rule. This rule tells you that NP(noun phrase) chunk should be formed whenever the chunker find the optional determiner(DJ) followed by any no. of adjectives and then a NN(noun).
Image after running above code.

Libraries like Spacy and TextBlob are best for chunking.
Named Entity Recognition
It is used to extract information from unstructured text. It is used to classy the entities which is present in the text into categories like a person, organization, event, places, etc. This will give you a detail knowledge about the text and the relationship between the different entities.
#Importing tokenization and chunk
from nltk.tokenize import word_tokenize from nltk import pos_tag, ne_chunk nltk.download( 'maxent_ne_chunker') nltk.download('words')
def ner(text):
# tokenize the text
word_tokens = word_tokenize(text)
# pos tagging of words
word_pos = pos_tag(word_tokens)
# tree of word entities
print(ne_chunk(word_pos))
text = 'Brain Lara scored the highest 400 runs in a test match which p ner(text)
In [ ]:
[nltk_data] Downloading package maxent_ne_chunker to [nltk_data] /root/nltk_data...
[nltk_data] Package maxent_ne_chunker is already up-to-date! [nltk_data] Downloading package words to /root/nltk_data... [nltk_data] Unzipping corpora/words.zip.
(S
(PERSON Brain/NNP) (PERSON Lara/NNP)
scored/VBD the/DT highest/JJS 400/CD
runs/NNS in/IN a/DT test/NN match/NN which/WDT
played/VBD in/IN between/IN
(ORGANIZATION WI/NNP)
and/CC
(GPE England/NNP)
./.)