What's spaCy?
SpaCy is free, open-source library for advanced Natural language processing(NLP) in Python.
Suppose you're working with a lot of text, you'll eventually want to know more about it. For example, what's it about? What does the words mean in the context? Who is doing what to
whom? What products and compnaies are mentioned in the text? Which texts are simmilar to each other.
spaCy is designed specifically for production use and helps you build applications that process and "understand" large volume of text. It can be used to build information extraction or natural language processing systems, or to pre-process text for deep learning.
What spaCy isn't?
First, spaCy isn't a platform or an "API". Unlike a platform, spaCy doesn't provide a software as a service or a web application. It’s an open-source library designed to help you build NLP applications, not a consumable service.
Second, spaCy is not an out-of-the-box chat bot engine. While spaCy can be used to power conversational applications, it’s not designed specifically for chat bots, and only provides the underlying text processing capabilities.
Third, spaCy is not research software. It’s built on the latest research, but it’s designed to get things done. This leads to fairly different design decisions than NLTK or CoreNLP, which were created as platforms for teaching and research. The main difference is that spaCy is integrated and opinionated. spaCy tries to avoid asking the user to choose between multiple algorithms that deliver equivalent functionality. Keeping the menu small lets spaCy deliver generally better performance and developer experience.
Fourth, spaCy is not a company It’s an open-source library.The company publishing spaCy and other software is called Explosion AI.
Installation
spaCy is compatible with 64bit of Cython 2.7/3.5+ and runs on Unix/Linux, macOS/OS X
and Windows. The latest version of spaCy is available over pip and conda.
--> Installation with pip in Linux,Windows and macOs/OS X for both version of Python 2.7/3.5+
pip install -U spacy or pip install spacy
--> Installation with conda in Linux,Windows and macOs/OS X for both version of Python 2.7/3.5+
conda install -c conda-forge spacy
Features
Here, you'll come across mentions of spaCy's features and capabilities.
Statistical models
Some of spaCy's features works independently, other requires statistical models to be loaded, which enable spaCy to predict linguistic annotations-For example, whether a word is a verb or noun. spaCy currently offers statistical models for a variety of languages, which can be
installed as individual Python modules. Models can differ in size, speed, memory usage, accuracy, and the data they include. The model you choose always depends upon your use cases and the texts you're working with. For a general use case, the small and the default models are always a good start. They typically include the following components:
Binary weights for the part-of-speech tagger, dependency parser and named entity recognizer to predict those annotations in context.
Lexical entries in the vocabulary, i.e. words and their context-independent attributes like the shape or spelling.
Data files like lemmatization rules and lookup tables.
Word vectors, i.e. multi-dimensional meaning representations of words that let you determine how similar they are to each other.
Configuration options, like the language and processing pipeline settings, to put spaCy in the correct state when you load in the model.
Linguistic annotations
spaCy provides a variety of linguistic annotations to give you insights into a text’s grammatical structure. This includes the word types, like the parts of speech, and how the words are related to each other. For example, if you’re analyzing text, it makes a huge difference whether a noun is the subject of a sentence, or the object – or whether “google” is used as a verb, or refers to the website or company in a specific context.
Once you’ve downloaded and installed (https://spacy.io/usage/models) a model, you can load it via spacy.load() This will return a Language object containing all components and data needed to process text. We usually call it nlp object on a string of text will return a processed Doc :
# https://spacy.io/usage/linguistic-features
import spacy
nlp = spacy.load( "en_core_web_sm")
doc = nlp( "Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text, token.pos_, token.dep_)
# Text: The original word text.
# Lemma: The base form of the word.
# POS: The simple part-of-speech tag.
# Tag: The detailed part-of-speech tag.
# Dep: Syntactic dependency, i.e. the relation between tokens. # Shape: The word shape – capitalization, punctuation, digits. # is alpha: Is the token an alpha character?
# is stop: Is the token part of a stop list, i.e. the most common word
In [11]:
Apple PROPN nsubj is AUX aux looking VERB ROOT at ADP prep buying VERB pcomp
U.K. PROPN compound startup NOUN dobj for ADP prep
$ SYM quantmod
1 NUM compound billion NUM pobj
Even though a Doc is processed - e.g. split into individual words and annotated - it still hols all information of the original text, like a whitespace characters. You can always get the offset of a token into the original string, or reconstruct the original by joining the tokens and their trailing whitespace. This way, you’ll never lose any information when processing text with spaCy.
Tokenization
During processing, spaCy first tokenizes the text, i.e. segments it into words, punctuation and so on. This is done by applying rules specific to each language. For example, punctuation at the end of a sentence should be split off – whereas “U.K.” should remain one token. Each
Doc consists of individual tokens, and we can iterate over them:
import spacy
nlp = spacy.load( "en_core_web_sm")
doc = nlp( "Apple is looking at buying U.K. startup for $1 billion")
for token in doc: print(token.text)
In [12]:
Apple is looking at buying U.K.
startup for
$ 1
billion

First, the raw text is split on whitespace characters, similar to text.split(' '). Then, the tokenizer processes the text from left to right. On each substring, it performs two checks:
-
Does the substring match a tokenizer exception rule? For example, “don’t” does not contain whitespace, but should be split into two tokens, “do” and “n’t”, while “U.K.” should always remain one token.
-
Can a prefix, suffix or infix be split off? For example punctuation like commas, periods, hyphens or quotes.
If there’s a match, the rule is applied and the tokenizer continues its loop, starting with the newly split substrings. This way, spaCy can split complex, nested tokens like combinations of abbreviations and multiple punctuation marks.
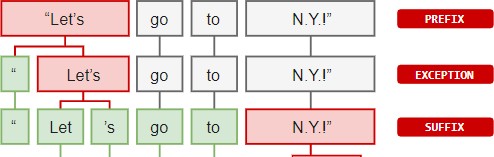
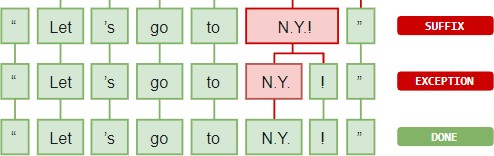
While punctuation rules are usually pretty general, tokenizer exceptions strongly depend on
import spacy
nlp = spacy.load( "en_core_web_sm")
doc = nlp( "Coronavirus: Delhi resident tests positive for coronavirus,
for token in doc:
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_ token.shape_, token.is_alpha, token.is_stop)
In [13]:
Coronavirus Coronavirus PROPN NNP ROOT Xxxxx True False
: : PUNCT : punct : False False
Delhi Delhi PROPN NNP ROOT Xxxxx True False resident resident NOUN NN amod xxxx True False tests test NOUN NNS nsubj xxxx True False positive positive ADJ JJ amod xxxx True False for for ADP IN prep xxx True True
coronavirus coronavirus PROPN NNP pobj xxxx True False
, , PUNCT , punct , False False
total total ADJ JJ ROOT xxxx True False
31 31 NUM CD nummod dd False False
people people NOUN NNS dobj xxxx True False infected infect VERB VBN acl xxxx True False in in ADP IN prep xx True True
India India PROPN NNP pobj Xxxxx True False
Using spaCy’s built-in displaCy visualizer, here’s what our example sentence and its dependencies look like:
import spacy
from spacy import displacy
nlp = spacy.load( "en_core_web_sm")
doc = nlp( "Google, Apple crack down on fake coronavirus apps") displacy.serve(doc, style = "dep")
In [14]:
Using the 'dep' visualizer
Serving on http://0.0.0.0:5000 (http://0.0.0.0:5000) ... Shutting down server on port 5000.
Named Entities
A named entity is a “real-world object” that’s assigned a name – for example, a person, a country, a product or a book title. spaCy can recognize various types of named entities in a document, by asking the model for a prediction. Because models are statistical and strongly depend on the examples they were trained on, this doesn’t always work perfectly and might need some tuning later, depending on your use case.
Named entities are available as the ents property of a Doc:
import spacy
nlp = spacy.load( "en_core_web_sm")
doc = nlp( "Coronavirus: Delhi resident tests positive for coronavirus,
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)
In [16]:
Delhi |
13 |
18 GPE |
31 66 |
68 |
CARDINAL |
India |
88 |
93 GPE |
Visualizing the Named Entity recognizer
The entity visualizer, ent , highlight named entities and their label in the text.
import spacy
from spacy import displacy
text = "Coronavirus: Delhi resident tests positive for coronavirus, to nlp = spacy.load( "en_core_web_sm")
doc = nlp(text) displacy.serve(doc, style = "ent")
# https://spacy.io/api/annotation#named-entities
In [0]:
C:\Users\User\Anaconda3\lib\runpy.py:193: UserWarning: [W011] It look s like you're calling displacy.serve from within a Jupyter notebook o r a similar environment. This likely means you're already running a l ocal web server, so there's no need to make displaCy start another on
e. Instead, you should be able to replace displacy.serve with displac y.render to show the visualization.
" main ", mod_spec)
displaCy
Coronavirus: Delhi GPE resident tests positive for coronavirus, total 31 CARDINAL
people infected in India GPE
Using the 'ent' visualizer
Serving on http://0.0.0.0:5000 (http://0.0.0.0:5000) ...
Words vector and similarity
Similarity is determined by comparing word vectors or “word embeddings”, multi-dimensional meaning representations of a word.Word vectors can be generated using an algorithm like
word2vec and usually look like this:
Important_note: To make them compact and fast, spaCy's small models(all the pacakages end with sm) don't ship with the word vectors, and only include context-sensitive tensors. This means you can still use the similarity() to compare documents, tokens and spans - but result won't be as good, and individual tokens won't have any vectors is assigned. So, in orders to use real word vectors, you need to download a larger model:
python -m spacy download en_core_web_md
Models that come with built-in word vectors make them available as the Token.vector attribute. Doc.vector and Span.vector will default to an average of their token vectors. You can also check if a token has a vector assigned, and get the L2 norm, which can be used to normalize vectors.
# !python -m spacy download en_core_web_md import spacy.cli spacy.cli.download( "en_core_web_md") import en_core_web_md
nlp = en_core_web_md.load()
In [17]:
✔ Download and installation successful
You can now load the model via spacy.load('en_core_web_md')
import spacy
nlp = spacy.load( "en_core_web_md")
tokens = nlp( "lion bear apple banana fadsfdshds")
for token in tokens:
print(token.text, token.has_vector, token.vector_norm, token.is_oo # Vector norm: The L2 norm of the token’s vector (the square root of t # has vector: Does the token have a vector representation?
# OOV: Out-of-vocabulary
In [18]:
lion True 6.5120897 False bear True 5.881604 False apple True 7.1346846 False banana True 6.700014 False fadsfdshds False 0.0 True
The words “lion”, “bear”, “apple” and "banana" are all pretty common in English, so they’re part of the model’s vocabulary, and come with a vector. The word “fadsfdshds” on the other hand is a lot less common and out-of-vocabulary – so its vector representation consists of 300 dimensions of 0, which means it’s practically nonexistent. If your application will benefit from a large vocabulary with more vectors, you should consider using one of the larger models or loading in a full vector package, for example, en_vectors_web_lg, which includes over 1 million unique vectors.
spaCy is able to compare two objects, and make a prediction of how similar they are.
Predicting similarity is useful for building recommendation systems or flagging duplicates. For example, you can suggest a user content that’s similar to what they’re currently looking at, or label a support ticket as a duplicate if it’s very similar to an already existing one.
Each Doc, Span and Token comes with a .similarity() method that lets you compare it with another object, and determine the similarity. Of course similarity is always subjective –
whether “dog” and “cat” are similar really depends on how you’re looking at it. spaCy’s similarity model usually assumes a pretty general-purpose definition of similarity.
import spacy
nlp = spacy.load( "en_core_web_md") # make sure to use larger model!
tokens = nlp( "lion bear cow apple mango spinach")
for token11 in tokens:
for token13 in tokens:
print(token11.text, token13.text, token11.similarity(token13))
In [20]:
lion lion 1.0
lion bear 0.6390859
lion cow 0.4780627
lion apple 0.33227408
lion mango 0.21551447
lion spinach 0.10201545
bear lion 0.6390859
bear bear 1.0
bear cow 0.43222296
bear apple 0.31760347
bear mango 0.19838898
bear spinach 0.125805
cow lion 0.4780627
cow bear 0.43222296
cow cow 1.0
cow apple 0.36605674
cow mango 0.28737056
cow spinach 0.318152
apple lion 0.33227408
apple bear 0.31760347
apple cow 0.36605674
apple apple 1.0
apple mango 0.6165637
apple spinach 0.43755493
mango lion 0.21551447
mango bear 0.19838898
mango cow 0.28737056
mango apple 0.6165637
mango mango 1.0
mango spinach 0.6105537
spinach lion 0.10201545
spinach bear 0.125805
spinach cow 0.318152
spinach apple 0.43755493
spinach mango 0.6105537
spinach spinach 1.0
In the above case you can see that "lion" and "bear" have a similarity of 63%. Identical tokens are obviously 100% similar to each other(just not always exactly 1.0, because of vector math and floating point imprecisions).
Pipelines
When you call nlp on a text, spaCy first tokenizes the text to produce a Doc object. The Doc is then processed in several different steps – this is also referred to as the processing pipeline. The pipeline used by the default models consists of a tagger, a parser and an entity recognizer. Each pipeline component returns the processed Doc, which is then passed on to the next component.

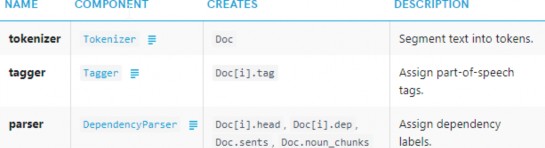
The processing pipeline always depends on the statistical model and its capabilities. For example, a pipeline can only include an entity recognizer component if the model includes data to make predictions of entity labels. This is why each model will specify the pipeline to use in its meta data, as a simple list containing the component names:
"pipeline": ["tagger", "parser", "ner"]
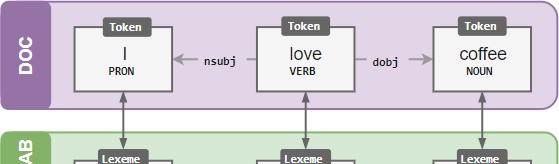
Vocab, hashes and lexemes
Whenever possible, spaCy tries to store data in a vocabulary, the Vocab, that will be shared by multiple documents. To save memory, spaCy also encodes all strings to hash values – in this case for example, “coffee” has the hash 3197928453018144401. Entity labels like “ORG”
and part-of-speech tags like “VERB” are also encoded. Internally, spaCy only “speaks” in hash values.
In [21]:
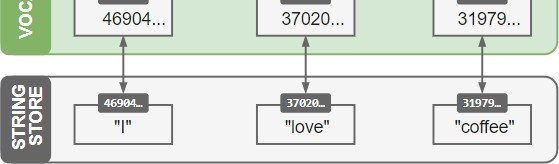
If you process lots of documents containing the word “coffee” in all kinds of different contexts, storing the exact string “coffee” every time would take up way too much space. So instead, spaCy hashes the string and stores it in the StringStore. You can think of the StringStore as a lookup table that works in both directions – you can look up a string to get its hash, or a
import spacy
nlp = spacy.load( "en_core_web_sm") doc = nlp( "I love coffee")
print(doc.vocab.strings[ "coffee"]) # 3197928453018144401
print(doc.vocab.strings[ 3197928453018144401]) # 'coffee'
3197928453018144401
coffee
# Let's check with other words like 'tea'
import spacy
nlp = spacy.load( "en_core_web_sm") doc = nlp( "I love tea, over coffee")
print(doc.vocab.strings[ "tea"]) # 6041671307218480733
print(doc.vocab.strings[ 6041671307218480733])
In [22]:
6041671307218480733
tea
Now that all strings are encoded, the entries in the vocabulary don’t need to include the word text themselves. Instead, they can look it up in the StringStore via its hash value. Each entry in the vocabulary, also called Lexeme, contains the context-independent information
import spacy
nlp = spacy.load( "en_core_web_sm") doc = nlp( "I love tea, over coffee!") for word in doc:
lexeme = doc.vocab[word.text]
# print(lexeme)
print(lexeme.text, lexeme.orth, lexeme.shape_, lexeme.prefix_, lex lexeme.is_alpha, lexeme.is_digit, lexeme.is_title, lexeme.
In [24]:
I 4690420944186131903 X I I True False True en
love 3702023516439754181 xxxx l ove True False False en tea 6041671307218480733 xxx t tea True False False en
, 2593208677638477497 , , , False False False en
over 5456543204961066030 xxxx o ver True False False en coffee 3197928453018144401 xxxx c fee True False False en
! 17494803046312582752 ! ! ! False False False en
The mapping of words to hashes doesn’t depend on any state. To make sure each value is unique, spaCy uses a hash function to calculate the hash based on the word string. This also means that the hash for “tea” will always be the same, no matter which model you’re using or how you’ve configured spaCy.
However, hashes cannot be reversed and there’s no way to resolve 6041671307218480733 back to “tea”. All spaCy can do is look it up in the vocabulary. That’s why you always need to make sure all objects you create have access to the same vocabulary. If they don’t, spaCy might not be able to find the strings it needs.
import spacy
from spacy.tokens import Doc
from spacy.vocab import Vocab
nlp = spacy.load( "en_core_web_sm")
doc = nlp( "I love tea, over coffee") # Original Doc print(doc.vocab.strings[ "tea"]) # 6041671307218480733 print(doc.vocab.strings[ 6041671307218480733]) # 'tea'
empty_doc = Doc(Vocab()) # New Doc with empty Vocab
# empty_doc.vocab.strings[6041671307218480733] will raise an error 🙁
empty_doc.vocab.strings.add("tea") # Add "tea" and generate hash
print(empty_doc.vocab.strings[ 6041671307218480733]) # 'tea'
new_doc = Doc(doc.vocab) # Create new doc with first doc's vocab
print(new_doc.vocab.strings[ 6041671307218480733]) # 'tea' 👍
In [0]:
6041671307218480733
tea tea tea
If the vocabulary doesn’t contain a string for 6041671307218480733, spaCy will raise an error. You can re-add “tea” manually, but this only works if you actually know that the document contains that word. To prevent this problem, spaCy will also export the Vocab when you save a Doc or nlp object. This will give you the object and its encoded annotations, plus the “key” to decode it.
Knowledge base
To support the entity linking task, spaCy stores external knowledge in a KnowledgeBase. The knowledge base (KB) uses the Vocab to store its data efficiently.
A knowledge base is created by first adding all entities to it. Next, for each potential mention or alias, a list of relevant KB IDs and their prior probabilities is added. The sum of these prior probabilities should never exceed 1 for any given alias.
from spacy.kb import KnowledgeBase
# load the model and create an empty KB
nlp = spacy.load( 'en_core_web_sm')
kb = KnowledgeBase(vocab =nlp.vocab, entity_vector_length = 3)
# adding entities
kb.add_entity(entity= "Q1004791", freq = 6, entity_vector =[ 0, 3, 5])
kb.add_entity(entity= "Q42", freq = 342, entity_vector =[ 1, 9, - 3])
kb.add_entity(entity= "Q5301561", freq = 12, entity_vector =[ - 2, 4, 2])
# adding aliases
kb.add_alias(alias= "Douglas", entities =[ "Q1004791", "Q42", "Q5301561"] kb.add_alias(alias = "Douglas Adams", entities =[ "Q42"], probabilities =[ 0
print()
print( "Number of entities in KB:",kb.get_size_entities()) # 3
print( "Number of aliases in KB:", kb.get_size_aliases()) # 2
In [0]:
Number of entities in KB: 3 Number of aliases in KB: 2
Candidate generation
Given a textual entity, the Knowledge Base can provide a list of plausible candidates or entity identifiers. The EntityLinker will take this list of candidates as input, and disambiguate the mention to the most probable identifier, given the document context.
import spacy
from spacy.kb import KnowledgeBase
nlp = spacy.load( 'en_core_web_sm')
kb = KnowledgeBase(vocab =nlp.vocab, entity_vector_length = 3)
# adding entities
kb.add_entity(entity= "Q1004791", freq = 6, entity_vector =[ 0, 3, 5])
kb.add_entity(entity= "Q42", freq = 342, entity_vector =[ 1, 9, - 3])
kb.add_entity(entity= "Q5301561", freq = 12, entity_vector =[ - 2, 4, 2])
# adding aliases
kb.add_alias(alias= "Douglas", entities =[ "Q1004791", "Q42", "Q5301561"]
candidates = kb.get_candidates( "Douglas")
for c in candidates:
print( " ", c.entity_, c.prior_prob, c.entity_vector)
In [0]:
Q1004791 0.6000000238418579 [0.0, 3.0, 5.0]
Q42 0.10000000149011612 [1.0, 9.0, -3.0]
Q5301561 0.20000000298023224 [-2.0, 4.0, 2.0]
Serialization
If you’ve been modifying the pipeline, vocabulary, vectors and entities, or made updates to the model, you’ll eventually want to save your progress – for example, everything that’s in your nlp object. This means you’ll have to translate its contents and structure into a format that can be saved, like a file or a byte string. This process is called serialization. spaCy comes with built-in serialization methods and supports the Pickle protocol.
All container classes, i.e. Language (nlp), Doc, Vocab and StringStore have the following methods available:

Training
spaCy’s models are statistical and every “decision” they make – for example, which part-of-speech tag to assign, or whether a word is a named entity – is a prediction. This prediction is based on the examples the model has seen during training. To train a model, you first need
training data – examples of text, and the labels you want the model to predict. This could be a part-of-speech tag, a named entity or any other information.
The model is then shown the unlabelled text and will make a prediction. Because we know the correct answer, we can give the model feedback on its prediction in the form of an error gradient of the loss function that calculates the difference between the training example and the expected output. The greater the difference, the more significant the gradient and the updates to our model.

When a training model, we don't want to memorize our examples- we want it to come up with theory that can be generalized with other examples. After all we don't just want the model to
learn that this one instance of "Amazon" right here is a company - we want it to learn that
"Amazon", in contexts like this, is most likely the company. That's why the training data should be representative always be the source of the data we want to process. A model is trained on wikipedia, where the sentences in the first person is to rare, will likely perform badly on
Twitter.Similarly, model trained on romantic novels will likely perform bad in legal text.
This also means that in order to know how the model is performing, and whether its learning the right things, you don't only need of training data- you'll also need evaluation data aswell. If you only test those data from which you trained, you will have no idea how well it's generalizing. If you want to train the model from scratch, you usually need at least 200 of
images for training and evaluation. To update the existing model, you can achieve decent results with very few examples - as long as they're representative.
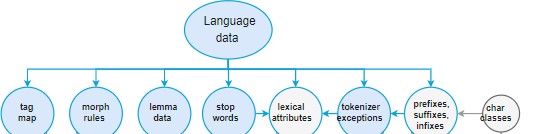
Language Data
Every language is different from each other and usually full of exceptions and special cases, especially the amongst the most common words. Some of these are shared across
languages, while others are entirely specific - usually it's to specific that they need to be hard-coded. The language module contains all the language-specific data, organized in simple
Python files. This makes the data easy to update and extend.
The shared language data in the directory root includes rules that can be generalized across languages – for example, rules for basic punctuation, emoji, emoticons, single-letter abbreviations and norms for equivalent tokens with different spellings, like " and ”. This helps the models make more accurate predictions. The individual language data in a submodule contains rules that are only relevant to a particular language. It also takes care of putting together all components and creating the Language subclass – for example, English or German.

In [0]: