StanfordNLP
StanfordNLP is a Python natural language analysis package. It contains tools, which can be used in a pipeline, to convert a string containing human language text into lists of sentences and words, to generate base forms of those words, their parts of speech and morphological features, and to give a syntactic structure dependency parse, which is designed to be parallel among more than 70 languages, using the Universal Dependencies formalism. In addition, it is able to call the CoreNLP Java package and inherits additonal functionality from there, such as constituency parsing, coreference resolution, and linguistic pattern matching.
This StanfordNLP package is built with highly accurate neural network components that enable efficient training and evaluation with your own annotated data. The modules are built on top of PyTorch. You will get much faster performance if you run this system on a GPU-enabled machine. This package is a combination of software based on the Stanford entry in the CoNLL 2018 Shared Task on Universal Dependency Parsing, and the group’s official Python interface to the Java Stanford CoreNLP software. The CoNLL UD system is partly a cleaned up version of code used in the shared task and partly an approximate rewrite in PyTorch of the original Tensorflow version of the tagger and parser.
Installation & Model Downlaod
Installation
For installing nlp run below command, always install StanfordNLP through PyPi ('https://pypi.org/') , once installed run in your comand line or anaconda prompt
pip install stanfordnlp
This will take care of all your necessary dependencies to run StanfordNLP. The neural pipeline of StanfordNLP depends on PyTorch 1.0.0 or a later version with compatible APIs.
Note: Installation in PyTorch.
For Conda(Works fine for Windows and Linux),
conda install pytorch torchvision cpuonly -c pytorch
Conda(Mac)
conda install pytorch torchvision -c pytorch
For Pip(Windows and Linux)
pip install torch==1.4.0+cpu torchvision==0.5.0+cpu -f http s://download.pytorch.org/whl/torch_stable.html
Pip(Mac)
pip install torch torchvision
In [1]:
!pip install stanfordnlp
Collecting stanfordnlp
Downloading https://files.pythonhosted.org/packages/41/bf/5d2898feb b6e993fcccd90484cba3c46353658511a41430012e901824e94/stanfordnlp-0.2.0
-py3-none-any.whl (https://files.pythonhosted.org/packages/41/bf/5d28 98febb6e993fcccd90484cba3c46353658511a41430012e901824e94/stanfordnlp-0.2.0-py3-none-any.whl) (158kB)
|████████████████████████████████| 163kB 2.7MB/s
Requirement already satisfied: tqdm in /usr/local/lib/python3.6/dist-packages (from stanfordnlp) (4.38.0)
Requirement already satisfied: requests in /usr/local/lib/python3.6/d ist-packages (from stanfordnlp) (2.21.0)
Requirement already satisfied: torch>=1.0.0 in /usr/local/lib/python 3.6/dist-packages (from stanfordnlp) (1.4.0)
Requirement already satisfied: numpy in /usr/local/lib/python3.6/dist
-packages (from stanfordnlp) (1.18.2)
Requirement already satisfied: protobuf in /usr/local/lib/python3.6/d ist-packages (from stanfordnlp) (3.10.0)
Requirement already satisfied: urllib3<1.25,>=1.21.1 in /usr/local/li b/python3.6/dist-packages (from requests->stanfordnlp) (1.24.3) Requirement already satisfied: chardet<3.1.0,>=3.0.2 in /usr/local/li b/python3.6/dist-packages (from requests->stanfordnlp) (3.0.4) Requirement already satisfied: idna<2.9,>=2.5 in /usr/local/lib/pytho n3.6/dist-packages (from requests->stanfordnlp) (2.8)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/p ython3.6/dist-packages (from requests->stanfordnlp) (2020.4.5.1) Requirement already satisfied: setuptools in /usr/local/lib/python3. 6/dist-packages (from protobuf->stanfordnlp) (46.1.3)
Requirement already satisfied: six>=1.9 in /usr/local/lib/python3.6/d ist-packages (from protobuf->stanfordnlp) (1.12.0)
Installing collected packages: stanfordnlp Successfully installed stanfordnlp-0.2.0
In [2]:
!pip install torch==1.4.0+cpu torchvision==0.5.0+cpu -f https://downlo
Looking in links: https://download.pytorch.org/whl/torch_stable.html (https://download.pytorch.org/whl/torch_stable.html)
Collecting torch==1.4.0+cpu
Downloading https://download.pytorch.org/whl/cpu/torch-1.4.0%2Bcpu-cp36-cp36m-linux_x86_64.whl (https://download.pytorch.org/whl/cpu/tor ch-1.4.0%2Bcpu-cp36-cp36m-linux_x86_64.whl) (127.2MB)
|████████████████████████████████| 127.2MB 94kB/s Collecting torchvision==0.5.0+cpu
Downloading https://download.pytorch.org/whl/cpu/torchvision-0.5.0% 2Bcpu-cp36-cp36m-linux_x86_64.whl (https://download.pytorch.org/whl/c pu/torchvision-0.5.0%2Bcpu-cp36-cp36m-linux_x86_64.whl) (5.4MB)
|████████████████████████████████| 5.4MB 30.6MB/s
Requirement already satisfied: numpy in /usr/local/lib/python3.6/dist
-packages (from torchvision==0.5.0+cpu) (1.18.2)
Requirement already satisfied: pillow>=4.1.1 in /usr/local/lib/python 3.6/dist-packages (from torchvision==0.5.0+cpu) (7.0.0)
Requirement already satisfied: six in /usr/local/lib/python3.6/dist-p ackages (from torchvision==0.5.0+cpu) (1.12.0)
Installing collected packages: torch, torchvision Found existing installation: torch 1.4.0
Uninstalling torch-1.4.0:
Successfully uninstalled torch-1.4.0 Found existing installation: torchvision 0.5.0
Uninstalling torchvision-0.5.0:
Successfully uninstalled torchvision-0.5.0 Successfully installed torch-1.4.0+cpu torchvision-0.5.0+cpu
import stanfordnlp
stanfordnlp.download('en') # This downloads the English models for t nlp = stanfordnlp.Pipeline() # This sets up a default neural pipeline doc = nlp( "Barack Obama was born in Hawaii. He was elected president doc.sentences[ 0].print_dependencies()
In [3]:
Using the default treebank "en_ewt" for language "en".
Would you like to download the models for: en_ewt now? (Y/n) Y
Default download directory: /root/stanfordnlp_resources Hit enter to continue or type an alternate directory.
Downloading models for: en_ewt
Download location: /root/stanfordnlp_resources/en_ewt_models.zip 100%|██████████| 235M/235M [00:23<00:00, 10.1MB/s]
Download complete. Models saved to: /root/stanfordnlp_resources/en_e wt_models.zip
Extracting models file for: en_ewt Cleaning up...Done.
Use device: cpu
---
Loading: tokenize With settings:
{'model_path': '/root/stanfordnlp_resources/en_ewt_models/en_ewt_toke nizer.pt', 'lang': 'en', 'shorthand': 'en_ewt', 'mode': 'predict'}
---
Loading: pos With settings:
{'model_path': '/root/stanfordnlp_resources/en_ewt_models/en_ewt_tagg er.pt', 'pretrain_path': '/root/stanfordnlp_resources/en_ewt_models/e n_ewt.pretrain.pt', 'lang': 'en', 'shorthand': 'en_ewt', 'mode': 'pre dict'}
---
Loading: lemma With settings:
{'model_path': '/root/stanfordnlp_resources/en_ewt_models/en_ewt_lemm atizer.pt', 'lang': 'en', 'shorthand': 'en_ewt', 'mode': 'predict'} Building an attentional Seq2Seq model...
Using a Bi-LSTM encoder
Using soft attention for LSTM. Finetune all embeddings.
[Running seq2seq lemmatizer with edit classifier]
---
Loading: depparse With settings:
{'model_path': '/root/stanfordnlp_resources/en_ewt_models/en_ewt_pars er.pt', 'pretrain_path': '/root/stanfordnlp_resources/en_ewt_models/e n_ewt.pretrain.pt', 'lang': 'en', 'shorthand': 'en_ewt', 'mode': 'pre dict'}
Done loading processors!
---
('Barack', '4', 'nsubj:pass')
('Obama', '1', 'flat')
('was', '4', 'aux:pass')
('born', '0', 'root')
('in', '6', 'case')
('Hawaii', '4', 'obl')
('.', '4', 'punct')
/pytorch/aten/src/ATen/native/LegacyDefinitions.cpp:19: UserWarning: masked_fill_ received a mask with dtype torch.uint8, this behavior is now deprecated,please use a mask with dtype torch.bool instead.
The last command here will print out the words in the first sentence in the input string (or Document, as it is represented in StanfordNLP), as well as the indices for the word that governs it in the Universal Dependencies parse of that sentence (its “head”), along with the dependency relation between the words.
Models for Human Languages
Downloading a language pack is as simple as
import stanfordnlp
#stanfordnlp.download('ar')
# replace "ar" with the language
In [0]:
To use default langauge pack for any language, simply build the pipeline as follows:
import stanfordnlp
nlp = stanfordnlp.Pipeline(lang="en") # This sets up a default neural doc = nlp( "Imran Khan was born in Pakistan. He became Prime minister." doc.sentences[ 0].print_dependencies()
In [1]:
ModuleNotFoundError Traceback (most recent call last)
Cell In[1], line 1
----> 1 import stanfordnlp
-
nlp = stanfordnlp.Pipeline(lang="en") # This sets up a defaul t neural pipeline in English
-
doc = nlp("Imran Khan was born in Pakistan. He became Prime m inister.")
ModuleNotFoundError: No module named 'stanfordnlp'
Pipeline
Users of StanfordNLP can process documents by building a Pipeline with the desired Processor units. The pipeline takes in a Document object or raw text, runs the processors in succession, and returns an annotated Document.
Options
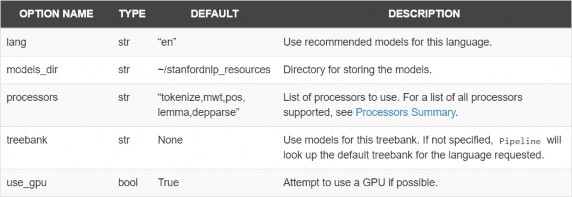
import stanfordnlp
MODELS_DIR = '.'
stanfordnlp.download('en', MODELS_DIR) # Download the English models nlp = stanfordnlp.Pipeline(processors ='tokenize,pos', models_dir=MODEL doc = nlp("Barack Obama was born in Hawaii.") # Run the pipeline on in doc.sentences[0].print_tokens() # Look at the result
In [6]:
Using the default treebank "en_ewt" for language "en".
Would you like to download the models for: en_ewt now? (Y/n) y
Downloading models for: en_ewt Download location: ./en_ewt_models.zip
100%|██████████| 235M/235M [00:10<00:00, 22.2MB/s]
Download complete. Models saved to: ./en_ewt_models.zip Extracting models file for: en_ewt
Cleaning up...Done. Use device: cpu
---
Loading: tokenize With settings:
{'model_path': './en_ewt_models/en_ewt_tokenizer.pt', 'lang': 'en', 'shorthand': 'en_ewt', 'mode': 'predict'}
---
Loading: pos With settings:
{'model_path': './en_ewt_models/en_ewt_tagger.pt', 'pretrain_path': './en_ewt_models/en_ewt.pretrain.pt', 'batch_size': 3000, 'lang': 'e n', 'shorthand': 'en_ewt', 'mode': 'predict'}
Done loading processors!
---
<Token index=1;words=[<Word index=1;text=Barack;upos=PROPN;xpos=NNP;f eats=Number=Sing>]>
<Token index=2;words=[<Word index=2;text=Obama;upos=PROPN;xpos=NNP;fe ats=Number=Sing>]>
<Token index=3;words=[<Word index=3;text=was;upos=AUX;xpos=VBD;feats= Mood=Ind|Number=Sing|Person=3|Tense=Past|VerbForm=Fin>]>
<Token index=4;words=[<Word index=4;text=born;upos=VERB;xpos=VBN;feat s=Tense=Past|VerbForm=Part|Voice=Pass>]>
<Token index=5;words=[<Word index=5;text=in;upos=ADP;xpos=IN;feats=_
>]>
<Token index=6;words=[<Word index=6;text=Hawaii;upos=PROPN;xpos=NNP;f eats=Number=Sing>]>
<Token index=7;words=[<Word index=7;text=.;upos=PUNCT;xpos=.;feats=_
>]>
Processors Summary
Processors are units of the neural pipeline that create different annotations for a Document. The neural pipeline now supports the following processors:



Data Objects
This section will describes the data objects used in StanfordNLP, and how they interact with each other.
Document
A Document object holds the annotation of an entire document, and is automatically generated when a string is annotated by the Pipeline. It holds a collection of Sentences, and can be seamlessly translated into a CoNLL-U file.
Objects of this class expose useful properties such as text, sentences, and conll_file.
Sentence
A Sentence object represents a sentence (as is predicted by the tokenizer), and holds a list of the Tokens in the sentence, as well as a list of all its Words. It also processes the dependency parse as is predicted by the parser, through its member method build_dependencies.
Objects of this class expose useful properties such as words, tokens, and dependencies, as well as methods such as print_tokens, print_words, print_dependencies.
Token
A Token object holds a token, and a list of its underlying words. In the event that the token is a multi-word token (e.g., French au = à le), the token will have a range index as described in the CoNLL-U format specifications (e.g., 3-4), with its word property containing the underlying Words. In other cases, the Token object will be a simple wrapper around one Word object, where its words property is a singleton.
Word
A Word object holds a syntactic word and all of its word-level annotations. In the example of multi-word tokens(MWT), these are generated as a result of multi-word token expansion, and are used in all downstream syntactic analyses such as tagging, lemmatization, and parsing. If a Word is the result from an MWT expansion, its text will usually not be found in the input raw text. Aside from multi-word tokens, Words should be similar to the familiar “tokens” one would see elsewhere.
TokenizeProcessor
Description
Tokenizes the text and performs sentence segmentation.

Options

Example
The tokenize processor is usually the first processor used in the pipeline. It performs tokenization and sentence segmentation at the same time After this processor is run the
import stanfordnlp
nlp = stanfordnlp.Pipeline(processors= 'tokenize', lang= 'en')
doc = nlp( "This is a test sentence for stanfordnlp. This is another se
for i, sentence in enumerate(doc.sentences): print( f"====== Sentence {i+1} tokens =======")
print(*[ f"index: {token.index.rjust(3)} \ttoken: {token.text} " for
In [0]:
Use device: cpu
---
Loading: tokenize With settings:
{'model_path': 'C:\\Users\\sudha\\stanfordnlp_resources\\en_ewt_model s\\en_ewt_tokenizer.pt', 'lang': 'en', 'shorthand': 'en_ewt', 'mode': 'predict'}
Done loading processors!
---
====== Sentence 1 tokens =======
index: |
1 |
token: |
This |
index: |
2 |
token: |
is |
index: |
3 |
token: |
a |
index: |
4 |
token: |
test |
index: |
5 |
token: |
sentence |
index: |
6 |
token: |
for |
index: |
7 |
token: |
stanfordnlp |
index: |
8 |
token: |
. |
====== |
Sentence |
2 tokens ======= |
|
index: |
1 |
token: This |
|
index: |
2 |
token: is |
|
index: |
3 |
token: another |
|
index: |
4 |
token: sentence |
|
index: |
5 |
token: . |
|
MWTProcessor
Description
Expands multi-word tokens(MWT) predicted by the tokenizer.

Options

Example
The mwt processor only requires tokenize. After these two processors have run, the Sentences will have lists of tokens and corresponding words based on the multi-word-token expander model. The list of tokens for sentence sent can be accessed with sent.tokens. The list of words for sentence sent can be accessed with sent.words. The list of words for a token token can be accessed with token.words. The code below shows an example of accessing tokens and words.
import stanfordnlp stanfordnlp.download( 'fr')
nlp = stanfordnlp.Pipeline(processors= 'tokenize,mwt', lang= 'fr')
doc = nlp( "Alors encore inconnu du grand public, Emmanuel Macron devie print(*[ f'token: {token.text.ljust(9)} \t\twords: {token.words} ' for se print( '')
print(*[ f'word: {word.text.ljust(9)} \t\ttoken parent:{word.parent_toke
In [0]:
Using the default treebank "fr_gsd" for language "fr".
Would you like to download the models for: fr_gsd now? (Y/n) Y
Default download directory: C:\Users\sudha\stanfordnlp_resources Hit enter to continue or type an alternate directory.
Downloading models for: fr_gsd
Download location: C:\Users\sudha\stanfordnlp_resources\fr_gsd_model s.zip
100%|████████████████████████████████████████████████████████████████
████████████████| 235M/235M [09:54<00:00, 418kB/s]
Download complete. Models saved to: C:\Users\sudha\stanfordnlp_resou rces\fr_gsd_models.zip
Extracting models file for: fr_gsd Cleaning up...Done.
Use device: cpu
---
Loading: tokenize With settings:
{'model_path': 'C:\\Users\\sudha\\stanfordnlp_resources\\fr_gsd_model s\\fr_gsd_tokenizer.pt', 'lang': 'fr', 'shorthand': 'fr_gsd', 'mode': 'predict'}
---
Loading: mwt With settings:
{'model_path': 'C:\\Users\\sudha\\stanfordnlp_resources\\fr_gsd_model s\\fr_gsd_mwt_expander.pt', 'lang': 'fr', 'shorthand': 'fr_gsd', 'mod e': 'predict'}
Building an attentional Seq2Seq model... Using a Bi-LSTM encoder
Using soft attention for LSTM. Finetune all embeddings.
Done loading processors!
---
token: Alors words: [<Word index=1;text=Alors>]
token: encore words: [<Word index=2;text=encore>]
token: inconnu words: [<Word index=3;text=inconnu>]
token: du words: [<Word index=4;text=de>, <Word index=5;text=le>]
token: grand words: [<Word index=6;text=grand>]
token: public words: [<Word index=7;text=public>]
token: , words: [<Word index=8;text=,>]
token: Emmanuel words: [<Word index=9;text=Emmanuel>]
token: Macron words: [<Word index=10;text=Macron>]
token: devient words: [<Word index=11;text=devient>]
token: en words: [<Word index=12;text=en>]
token: 2014 words: [<Word index=13;text=2014>]
token: ministre words: [<Word index=14;text=ministre
>]
token: de words: [<Word index=15;text=de>]
token: l' words: [<Word index=16;text=l'>]
token: Économie words: [<Word index=17;text=Économie
>]
token: , words: [<Word index=18;text=,>]
token: de words: [<Word index=19;text=de>]
token: l' words: [<Word index=20;text=l'>]
token: Industrie words: [<Word index=21;text=Industrie
>]
token: et words: [<Word index=22;text=et>]
token: du words: [<Word index=23;text=de>, <Wor d index=24;text=le>]
token: Numérique words: [<Word index=25;text=Numérique
>]
token: . words: [<Word index=26;text=.>]
word: Alors token parent:1-Alors
word: encore token parent:2-encore
word: |
inconnu |
token |
parent:3-inconnu |
word: |
de |
token |
parent:4-5-du |
word: |
le |
token |
parent:4-5-du |
word: |
grand |
token |
parent:6-grand |
word: |
public |
token |
parent:7-public |
word: |
, |
token |
parent:8-, |
word: |
Emmanuel |
token |
parent:9-Emmanuel |
word: |
Macron |
token |
parent:10-Macron |
word: |
devient |
token |
parent:11-devient |
word: |
en |
token |
parent:12-en |
word: |
2014 |
token |
parent:13-2014 |
word: |
ministre |
token |
parent:14-ministre |
word: |
de |
token |
parent:15-de |
word: |
l' |
token |
parent:16-l' |
word: |
Économie |
token |
parent:17-Économie |
word: |
, |
token |
parent:18-, |
word: |
de |
token |
parent:19-de |
word: |
l' |
token |
parent:20-l' |
word: |
Industrie |
token |
parent:21-Industrie |
word: |
et |
token |
parent:22-et |
word: |
de |
token |
parent:23-24-du |
word: |
le |
token |
parent:23-24-du |
word: |
Numérique |
token |
parent:25-Numérique |
word: |
. |
token |
parent:26-. |
POSProcessor
Description

Labels tokens with their universal POS (UPOS) tags, treebank-specific POS (XPOS) tags, and universal morphological features (UFeats).
Options

Example
In [0]:
|
import stanfordnlp nlp = stanfordnlp.Pipeline(processors='tokenize,mwt,pos') doc = nlp( "Barack Obama was born in Hawaii.") print(*[f'word: {word.text+" "} \tupos: {word.upos}\txpos: {word.xpos}' |
||
|
|
|
|
Use device: cpu
---
Loading: tokenize With settings:
{'model_path': 'C:\\Users\\sudha\\stanfordnlp_resources\\en_ewt_model s\\en_ewt_tokenizer.pt', 'lang': 'en', 'shorthand': 'en_ewt', 'mode': 'predict'}
---
Loading: pos With settings:
{'model_path': 'C:\\Users\\sudha\\stanfordnlp_resources\\en_ewt_model s\\en_ewt_tagger.pt', 'pretrain_path': 'C:\\Users\\sudha\\stanfordnlp
_resources\\en_ewt_models\\en_ewt.pretrain.pt', 'lang': 'en', 'shorth and': 'en_ewt', 'mode': 'predict'}
Done loading processors!
---
word: Barack upos: PROPN xpos: NNP word: Obama upos: PROPN xpos: NNP word: was upos: AUX xpos: VBD word: born upos: VERB xpos: VBN word: in upos: ADP xpos: IN word: Hawaii upos: PROPN xpos: NNP word: . upos: PUNCT xpos: .
LemmaProcessor
Description
Generates the word lemmas for all tokens in the corpus.

Options




import stanfordnlp
nlp = stanfordnlp.Pipeline(processors= 'tokenize,mwt,pos,lemma') doc = nlp( "Barack Obama was born in Hawaii.")
print(*[ f'word: {word.text+ " "} \tlemma: {word.lemma} ' for sent in doc.
In [0]:
Use device: cpu
---
Loading: tokenize With settings:
{'model_path': 'C:\\Users\\sudha\\stanfordnlp_resources\\en_ewt_model s\\en_ewt_tokenizer.pt', 'lang': 'en', 'shorthand': 'en_ewt', 'mode': 'predict'}
---
Loading: pos With settings:
{'model_path': 'C:\\Users\\sudha\\stanfordnlp_resources\\en_ewt_model s\\en_ewt_tagger.pt', 'pretrain_path': 'C:\\Users\\sudha\\stanfordnlp
_resources\\en_ewt_models\\en_ewt.pretrain.pt', 'lang': 'en', 'shorth and': 'en_ewt', 'mode': 'predict'}
---
Loading: lemma With settings:
{'model_path': 'C:\\Users\\sudha\\stanfordnlp_resources\\en_ewt_model s\\en_ewt_lemmatizer.pt', 'lang': 'en', 'shorthand': 'en_ewt', 'mod e': 'predict'}
Building an attentional Seq2Seq model... Using a Bi-LSTM encoder
Using soft attention for LSTM. Finetune all embeddings.
[Running seq2seq lemmatizer with edit classifier] Done loading processors!
---
word: Barack lemma: Barack word: Obama lemma: Obama word: was lemma: be
word: born lemma: bear
word: in lemma: in word: Hawaii lemma: Hawaii word: . lemma: .
DepparseProcessor
Description
Provides an accurate syntactic dependency parser.

Options

Example
The depparse processor depends on tokenize, mwt, pos, and lemma. After all these processors have been run, each Sentence in the output would have been parsed into Universal Dependencies structure, where the governor index of each word can be accessed by word.governor, and the dependency relation between the words word.dependency_relation. Note that the governor index starts at 1 for actual words, and is 0 only when the word itself is the root of the tree. This index should be offset by 1 when looking for the govenor word in the sentence. Here is an example to access dependency parse information:
import stanfordnlp
nlp = stanfordnlp.Pipeline(processors= 'tokenize,mwt,pos,lemma,depparse doc = nlp( "Van Gogh grandit au sein d'une famille de l'ancienne bourge print(*[ f"index: {word.index.rjust(2)} \tword: {word.text.ljust(11)} \tg
In [0]:
Use device: cpu
---
Loading: tokenize With settings:
{'model_path': 'C:\\Users\\sudha\\stanfordnlp_resources\\fr_gsd_model s\\fr_gsd_tokenizer.pt', 'lang': 'fr', 'shorthand': 'fr_gsd', 'mode': 'predict'}
---
Loading: mwt With settings:
{'model_path': 'C:\\Users\\sudha\\stanfordnlp_resources\\fr_gsd_model s\\fr_gsd_mwt_expander.pt', 'lang': 'fr', 'shorthand': 'fr_gsd', 'mod e': 'predict'}
Building an attentional Seq2Seq model... Using a Bi-LSTM encoder
Using soft attention for LSTM. Finetune all embeddings.
---
Loading: pos With settings:
{'model_path': 'C:\\Users\\sudha\\stanfordnlp_resources\\fr_gsd_model s\\fr_gsd_tagger.pt', 'pretrain_path': 'C:\\Users\\sudha\\stanfordnlp
_resources\\fr_gsd_models\\fr_gsd.pretrain.pt', 'lang': 'fr', 'shorth and': 'fr_gsd', 'mode': 'predict'}
---
Loading: lemma With settings:
{'model_path': 'C:\\Users\\sudha\\stanfordnlp_resources\\fr_gsd_model s\\fr_gsd_lemmatizer.pt', 'lang': 'fr', 'shorthand': 'fr_gsd', 'mod e': 'predict'}
Building an attentional Seq2Seq model... Using a Bi-LSTM encoder
Using soft attention for LSTM. Finetune all embeddings.
[Running seq2seq lemmatizer with edit classifier]
---
Loading: depparse With settings:
{'model_path': 'C:\\Users\\sudha\\stanfordnlp_resources\\fr_gsd_model s\\fr_gsd_parser.pt', 'pretrain_path': 'C:\\Users\\sudha\\stanfordnlp
_resources\\fr_gsd_models\\fr_gsd.pretrain.pt', 'lang': 'fr', 'shorth and': 'fr_gsd', 'mode': 'predict'}
Done loading processors!
---
..\aten\src\ATen\native\LegacyDefinitions.cpp:19: UserWarning: masked
_fill_ received a mask with dtype torch.uint8, this behavior is now d eprecated,please use a mask with dtype torch.bool instead.
index: 1 word: Van governor index: 3 gover nor: grandit deprel: nsubj
index: 2 word: Gogh governor index: 1 gover nor: Van deprel: flat:name
index: 3 word: grandit governor index: 0 gover nor: root deprel: root
index: 4 word: à governor index: 6 gover nor: sein deprel: case
index: 5 word: le governor index: 6 gover nor: sein deprel: det
index: 6 word: sein governor index: 3 gover nor: grandit deprel: obl
index: 7 word: d' governor index: 9 gover nor: famille deprel: case
index: 8 word: une governor index: 9 gover nor: famille deprel: det
index: 9 word: famille governor index: 6 gover nor: sein deprel: nmod
index: 10 word: de governor index: 13 gover nor: bourgeoisie deprel: case
index: 11 word: l' governor index: 13 gover nor: bourgeoisie deprel: det
index: 12 word: ancienne governor index: 13 gover nor: bourgeoisie deprel: amod
index: 13 word: bourgeoisie governor index: 9 gover nor: famille deprel: nmod
index: 14 word: . governor index: 3 gover nor: grandit deprel: punct
In [0]: